Ngunnawal & Ngambri Country
Embodied Music Generation
-
note generation: generate “symbolic” music—notes (A, B, C, half-note, quaver, etc.). Abstract version of sounds created by some musical instruments.
-
embodied gesture generation: generate the movements a performer makes to operate a particular musical instrument.
this project explores embodied gesture generation in an improvised electronic music context!
Embodied Predictive Musical Instrument (EMPI)
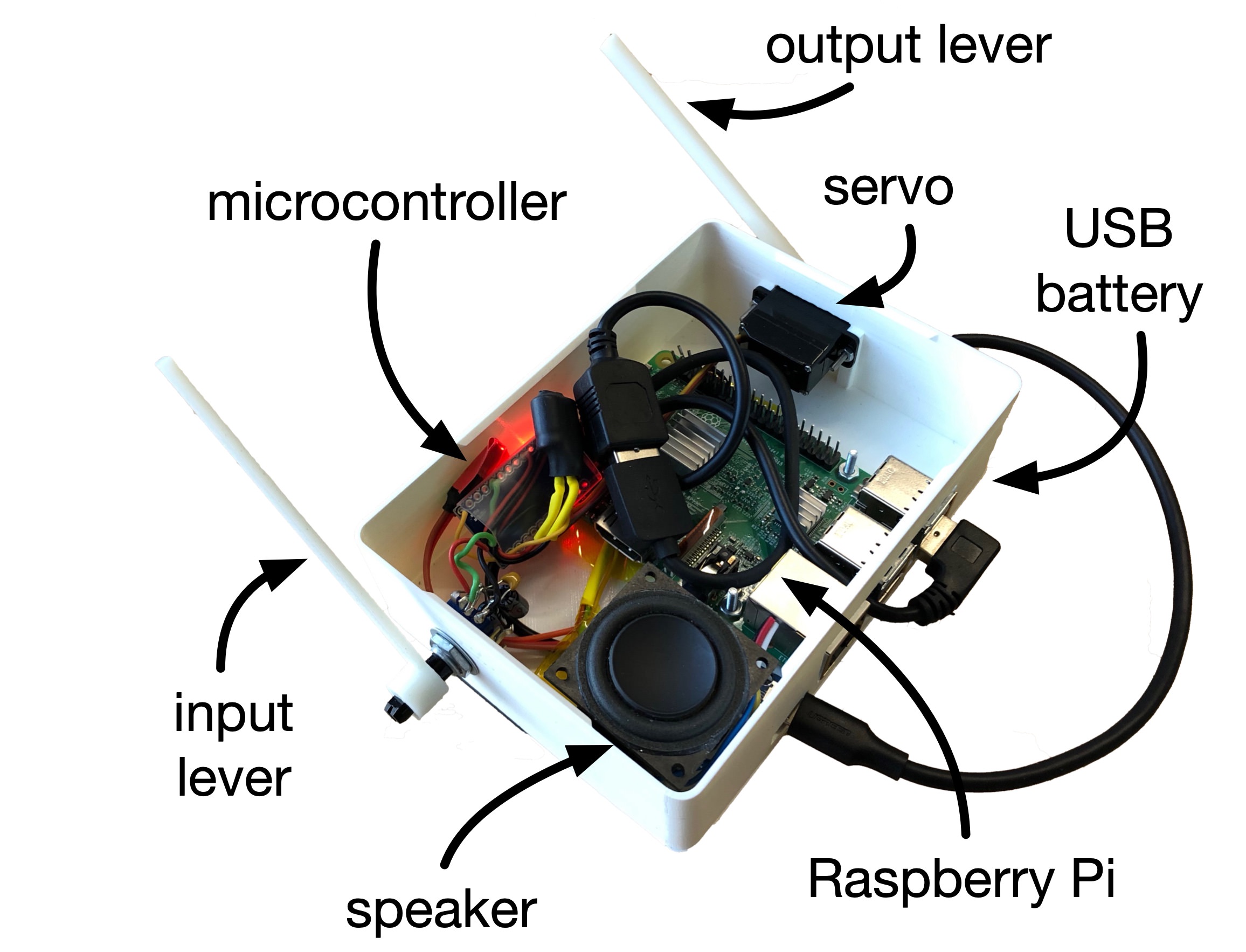
- Predicts next movement and time, represents physically.
- Experiments with interaction mappings; mainly focussed on call-response
- Weird and confusing/fun?
Generative AI System
-
gestural predictions are made by a Mixture Density Recurrent Neural Network (implemented using “Interactive Music Prediction System”—IMPS - see NIME ‘19 paper)
-
MDRNN: an extension of common LSTM/RNN designs to allow expressive predictions of multiple continuous variables.
-
MDRNN specs: 2 32-unit LSTM layers, 2-dimensional mixture density layer (arm position + time)
-
IMPS: A CLI Python program that provides MDRNN, data collection, training and interaction features.
-
communicates with music software over OSC (Open Sound Control)
-
in this case, MDRNN is configured for “call-and-response” interaction (or “continuation”)
Training Data
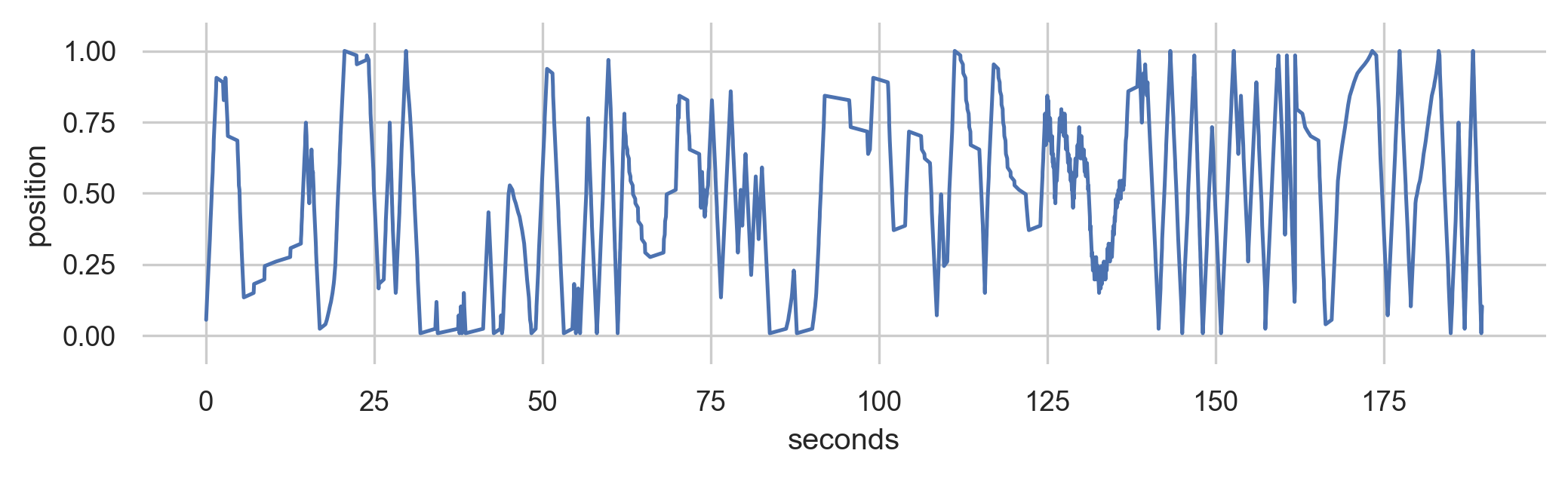
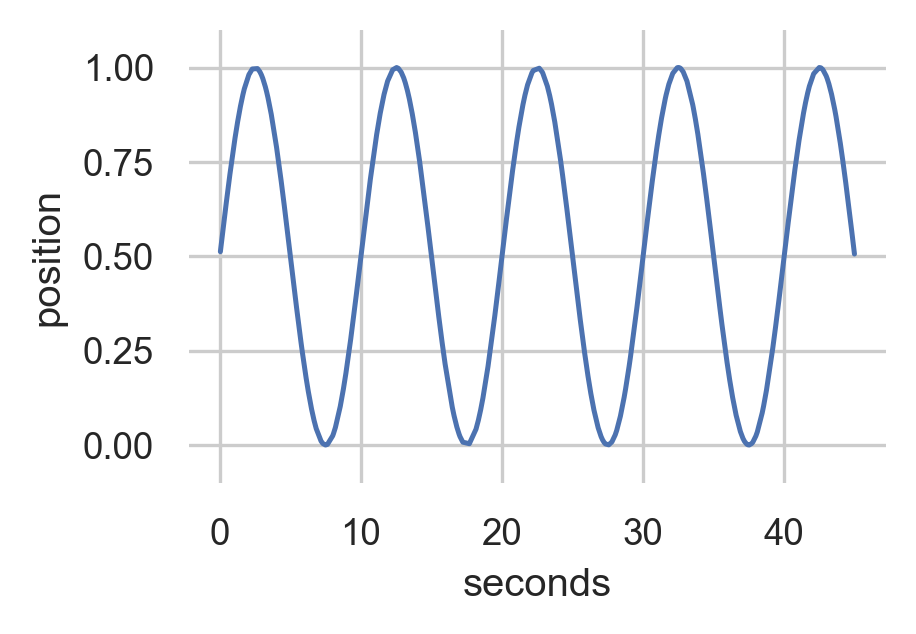
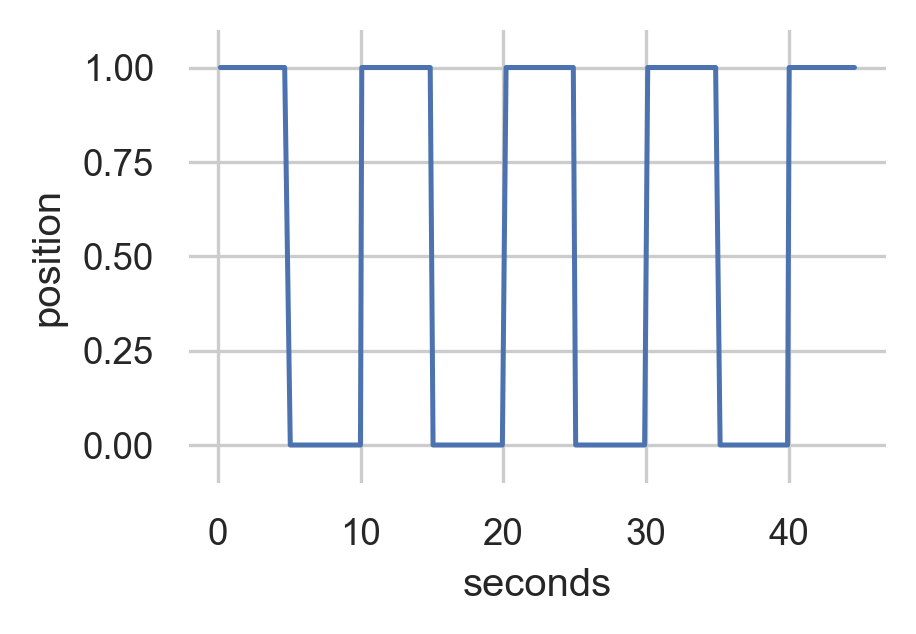
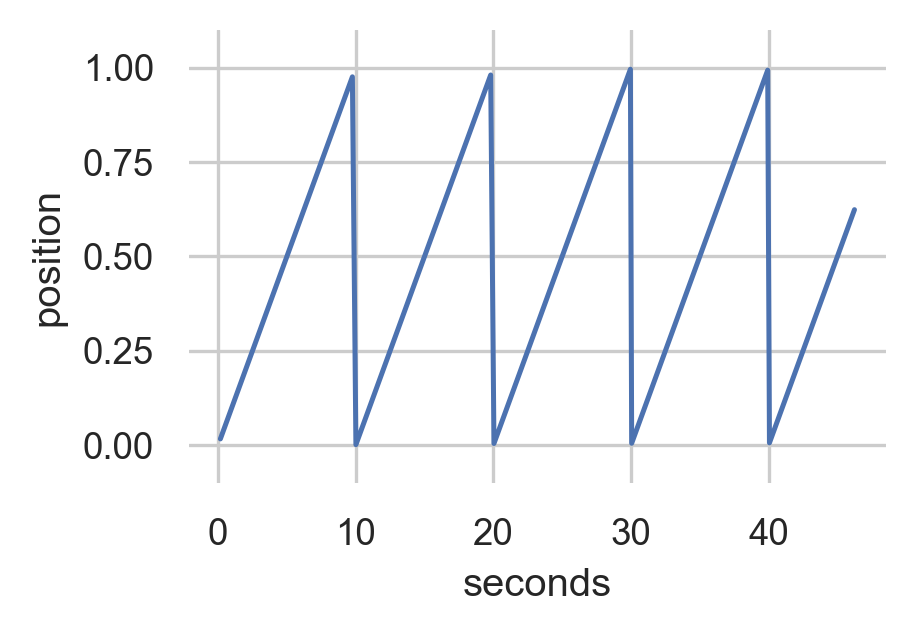
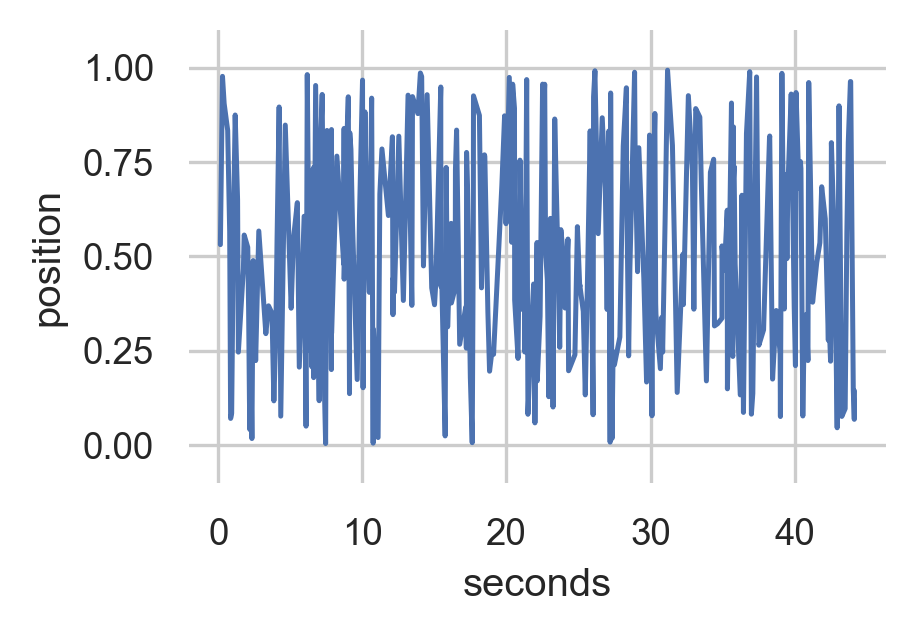
Generated Data
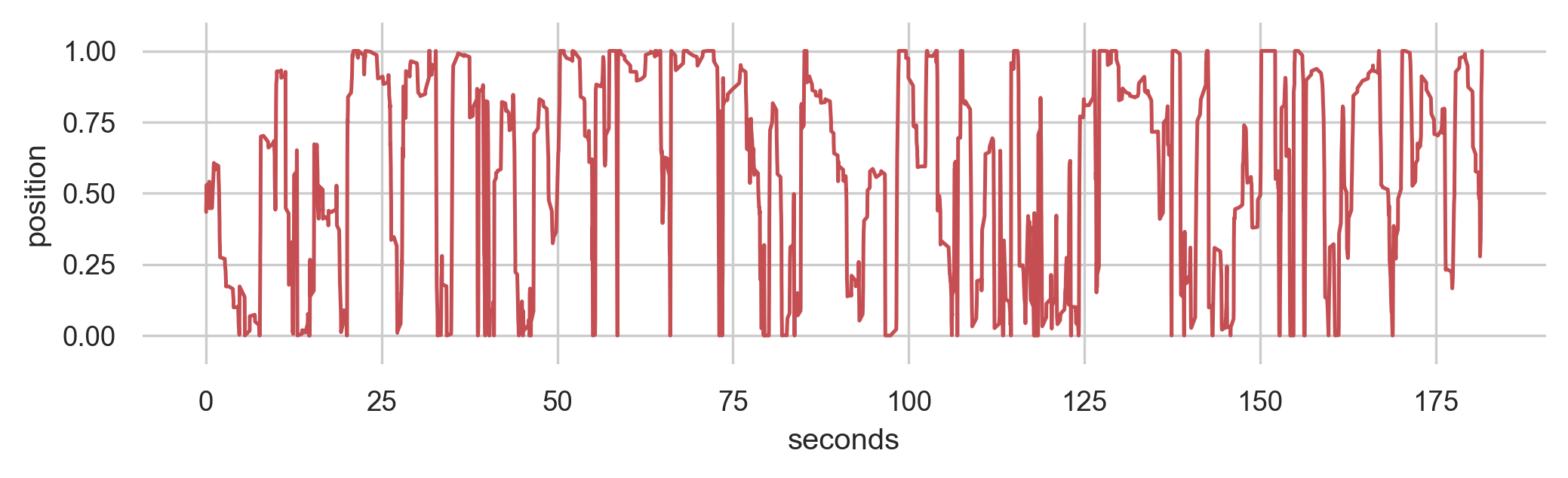
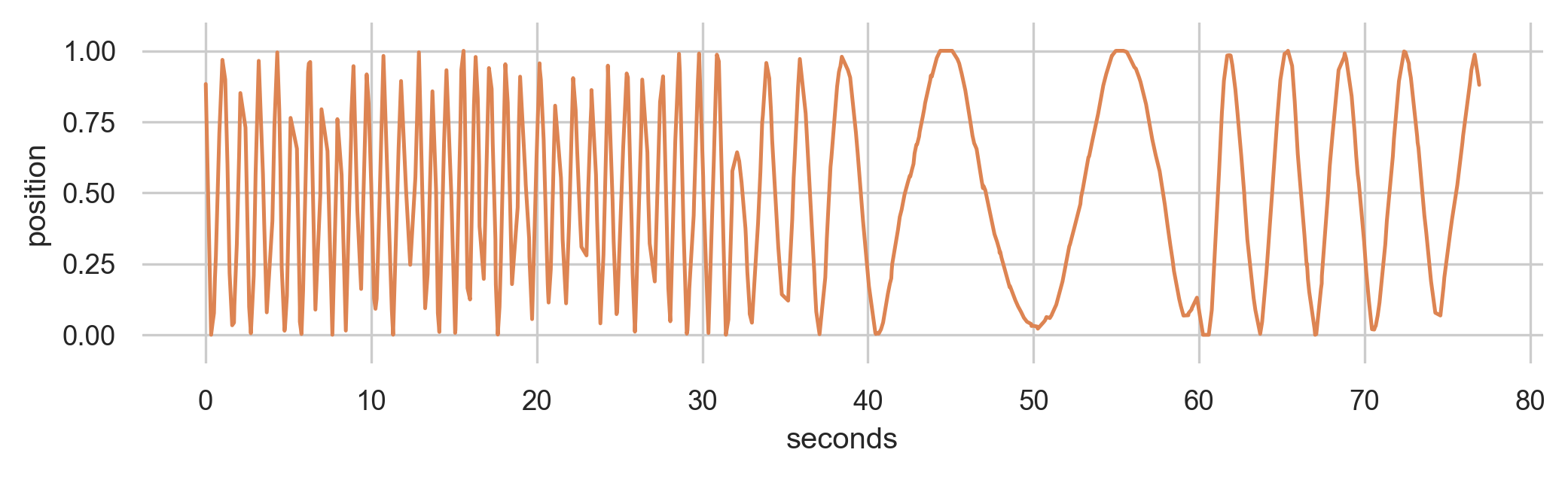
Improvisations with EMPI
-
12 participants
-
two independent factors: model and feedback
-
model: human, synthetic, noise
-
feedback: motor on, motor off
Results: Survey
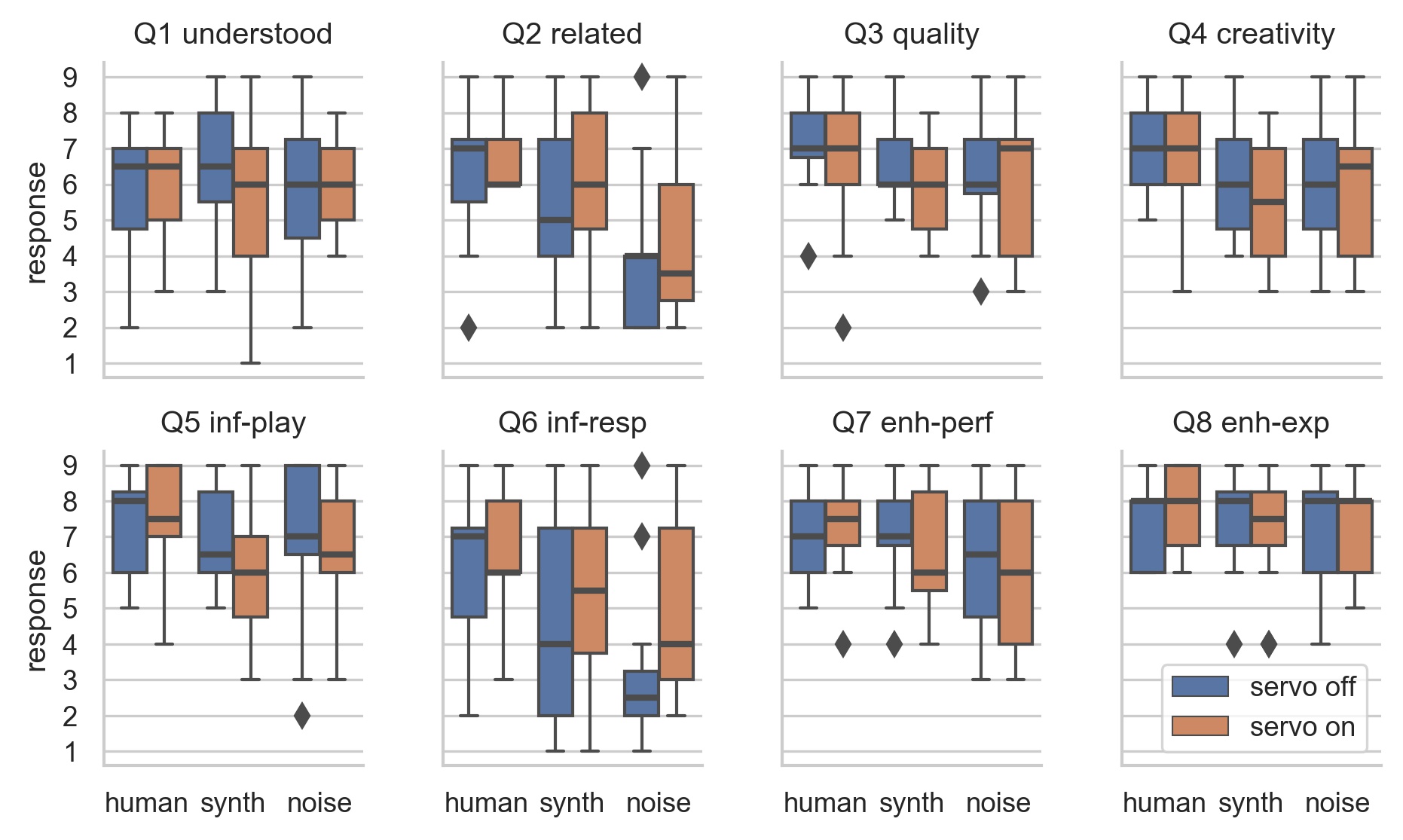
Change of ML model had significant effect: Q2, Q4, Q5, Q6, Q7
Results: Survey
-
human model most “related”, noise was least
-
human model most “musically creative”
-
human model easiest to “influence”
-
noise model not rated badly!
Participants generally preferred human or synth, but not always!
Results: Performance Length
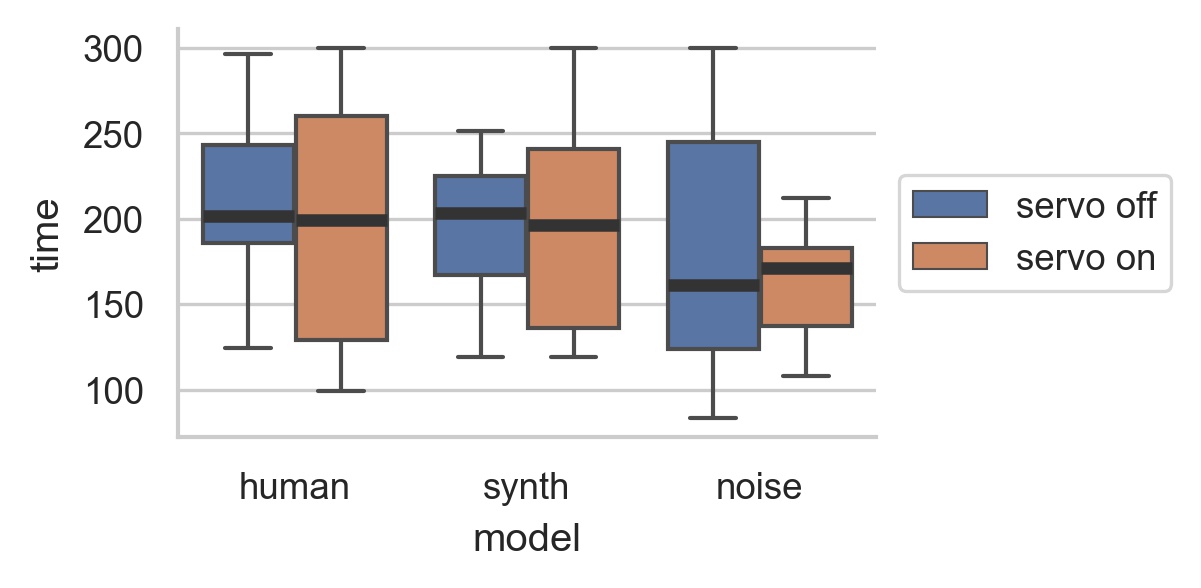
Human and synth: more range of performance lengths with motor on.
Noise: more range with motor off.
Takeaways
Studied self-contained intelligent instrument in genuine performance.
Physical representation could be polarising.
Performers work hard to understand and influence ML model.
Constrained, intelligent instrument can produce a compelling experience.
Thanks!
- EMPI on GitHub
- creative ML: creativeprediction.xyz
- Twitter/Github: @cpmpercussion
- Homepage: charlesmartin.com.au
Charles Patrick Martin and Jim Torresen. 2019. An Interactive Musical Prediction System with Mixture Density Recurrent Neural Networks. Proceedings of the International Conference on New Interfaces for Musical Expression, UFRGS, pp. 260–265.
Charles Patrick Martin, Kyrre Glette, Tønnes Frostad Nygaard, and Jim Torresen. 2020. Understanding Musical Predictions with an Embodied Interface for Musical Machine Learning. Frontiers in Artificial Intelligence 3, 6. http://doi.org/10.3389/frai.2020.00006